We have barely scratched the surface of the universe of classification algorithms. But even just the two types we have seen, nearest neighbors and decision trees, have multiple variations and options available through hyperparameters.
Definition 4.1 A hyperparameter of a learning algorithm is a value or setting affecting the algorithm that remains fixed throughout training.
Note
In machine learning, a parameter is a value that is adjusted during training; i.e., it is learned from the training data. In most of mathematics, we would refer to these as variables, but in ML that term is often understood to be synonymous with feature.
Some hyperparameters, such as the choice of norm in the nearest-neighbors algorithm, have an influence that is not easy to characterize. But others clearly affect the potential expressive power of the algorithm.
Example 4.1 The maximum depth \(r\) of a decision tree limits the complexity that the tree can attain. When \(r=1\), the tree can divide the data only once and assign one or two different labels. In general, though, a tree can assign up to \(2^r\) unique labels, which grows exponentially with \(r\); in fact, any training set of that size or smaller can be modeled with 100% training accuracy.
For a kNN classifier, when \(k\) is as large as the number of samples, the classifier can only take one value on the entire set—all the samples have a vote everywhere. The other extreme is \(k=1\), where each sample rules within its own neighborhood, and again we achieve 100% training accuracy.
Options provide valuable flexibility but also demand rationales for their use. How can we choose the best hyperparameters for a given problem? And how do we choose the best algorithm overall? In order to answer these questions, we must first understand what to expect from the results of a learner in general terms.
4.1 Bias–variance tradeoff
When we train a classifier, we use a particular set of training data. In a different parallel universe, we might have been handed a different training set drawn from the same overall population. While we might be optimistic and hope for receiving the best-case training set, it’s more prudent to consider what happens in the average case.
4.1.1 Learner bias
Suppose that \(f(x)\) is a perfect labeller, i.e., a function with 100% accuracy over an entire population. For simplicity, we can imagine that \(f\) is a binary classifier, i.e., \(f(x) \in \{0,1\}\), although this assumption is not essential.
Let \(\hat{f}(x)\) denote a probabilistic classification function obtained after training. It depends on the particular training set we used. Suppose there are \(N\) total possible training sets, leading to labelling functions \[
\hat{f}_1(x),\hat{f}_2(x),\dots,\hat{f}_N(x).
\]
Then we define the expected value of the classifier as the average over all training sets: \[
\E{\hat{f}(x)} = \frac{1}{N} \sum_{i=1}^N \hat{f_i}(x).
\]
Note
Except on toy problems, we don’t know how to calculate this average. This is more of a thought experiment. But we do simulate the process later on.
The term expected doesn’t mean that we anticipate getting this answer for our particular instance of \(\hat{f}\). It’s just what we would get if we could average over all parallel universes receiving unique training sets.
We can apply the expectation operator \(\mathbb{E}\) to any function of \(x\). In particular, the expected error in our own universe’s prediction is \[
\begin{split}
\E{f(x) - \hat{f}(x)} &= \frac{1}{N} \sum_{i=1}^N \left( f(x) - \hat{f_i}(x) \right) \\
&= \frac{1}{N} \left( \sum_{i=1}^N f(x) \right) - \frac{1}{N}\left( \sum_{i=1}^N \hat{f_i}(x) \right) \\
&= f(x) - \E{\hat{f}(x)}.
\end{split}
\]
Definition 4.2 The bias of a method \(\hat{f}(x)\) for learning the labeler \(f(x)\) is the expected difference between the true label and the expected prediction, \(f(x) - \E{\hat{f}(x)}\).
We often set \(y=f(x)\) as the true label and \(\hat{y}=\E{\hat{f}(x)}\) as the expected prediction, allowing us to write the bias as \(y-\hat{y}\).
Bias depends on the particular learning algorithm and its hyperparameters, but not on the training set. Among other things, bias accounts for the fact that any particular finite algorithm can represent only a finite number of labelling functions perfectly.
4.1.2 Variance
It might seem as though the only important goal in machine learning is to minimize the bias. To see why this is not the case, imagine that you are playing a hole of golf where the green lies on an island at the end of the fairway. You’re capable of landing the ball on the green in one swing, but it’s near the upper end of your range, and the penalty for landing in the water instead is severe. You might be better off playing it safe by just approaching the water’s edge, which is a shot you can make much more reliably. On average over many attempts, you may well get a better score on the hole from the aggressive strategy, but the safe strategy gives you a more reliable result and better odds of doing fairly well, though not optimally.
In essence, a good chance of a mediocre result can outweigh a small chance of a better result. To express this tradeoff mathematically, we can compute the variance of the predicted label at any \(x\): \[
\begin{split}
\E{\bigl(y - \hat{f}(x)\bigr)^2} &= \frac{1}{N} \sum_{i=1}^N \left( y - \hat{f_i}(x) \right)^2 \\
&= \frac{1}{N} \sum_{i=1}^N \left( y - \hat{y} + \hat{y} - \hat{f_i}(x) \right)^2 \\
&= \frac{1}{N} \sum_{i=1}^N \left( y - \hat{y} \right)^2 + \frac{1}{N} \sum_{i=1}^N \left( \hat{y} - \hat{f}_i(x) \right)^2 \\
& \qquad + 2 \left( y - \hat{y} \right) \cdot \frac{1}{N}\sum_{i=1}^N \left( \hat{y} - \hat{f}_i(x) \right).
\end{split}
\]
where \(\hat{y} = \E{\hat{f}(x)}\) is the expected prediction.
You might think of a method’s variance as the inverse of its repeatability or stability.
To summarize Equation 4.1, the variance of a prediction has two contributions:
Method bias
How close is the average prediction to the ground truth?
Method variance
How close to the average prediction is any one prediction likely to be?
Code
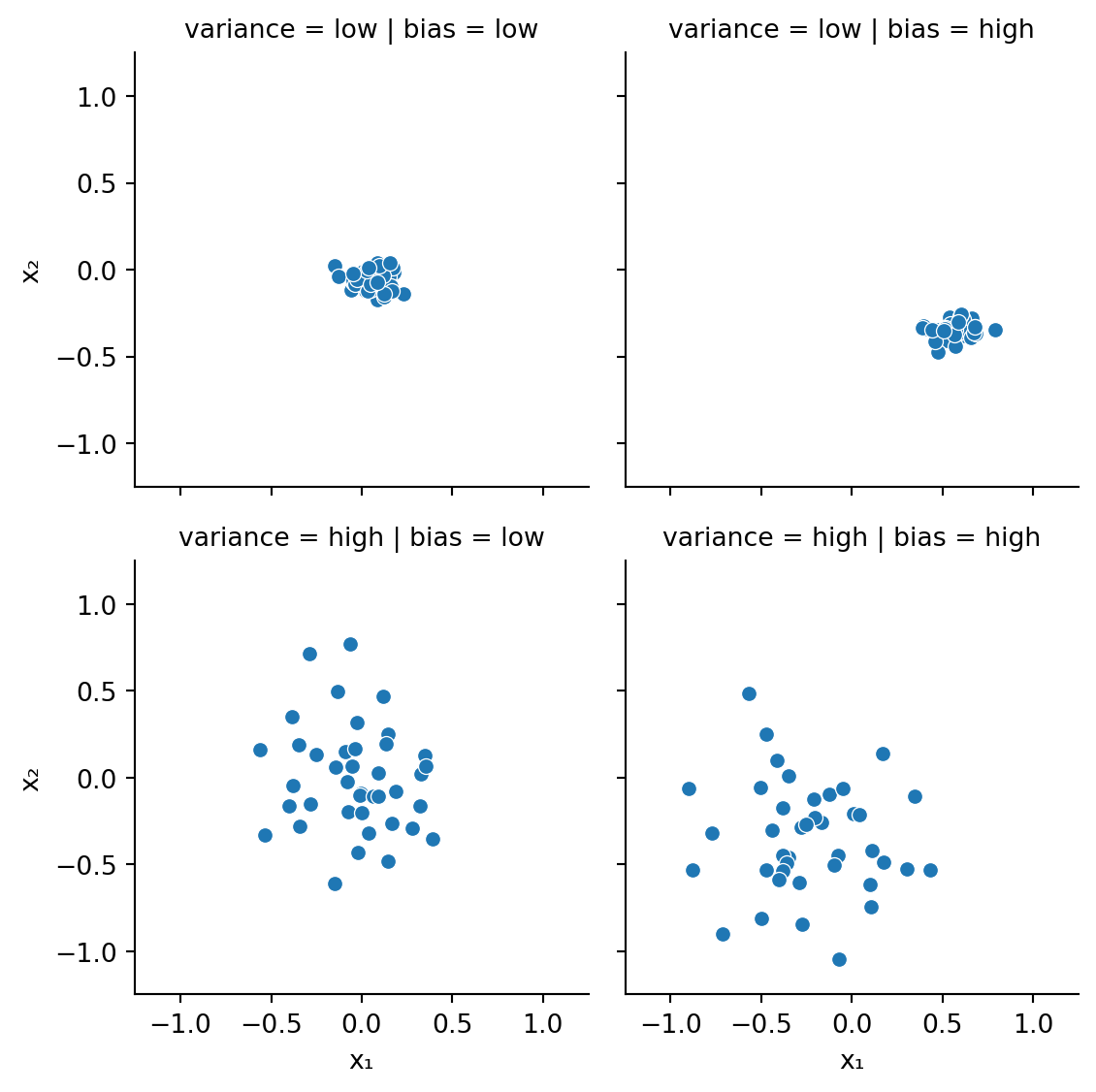
rng = default_rng(302)x, y, bias, var = [], [], [], []x.extend(rng.normal(0.04,0.08,40))y.extend(rng.normal(-0.03,0.06,40))bias.extend(["low"]*40)var.extend(["low"]*40)x.extend(rng.normal(0.55,0.11,40))y.extend(rng.normal(-0.35,0.05,40))bias.extend(["high"]*40)var.extend(["low"]*40)x.extend(rng.normal(-0.02,0.34,40))y.extend(rng.normal(0.03,0.33,40))bias.extend(["low"]*40)var.extend(["high"]*40)x.extend(rng.normal(-0.25,0.33,40))y.extend(rng.normal(-0.35,0.33,40))bias.extend(["high"]*40)var.extend(["high"]*40)points = pd.DataFrame({"bias": bias, "variance": var, "x₁": x, "x₂": y})fig = sns.relplot(data=points, x="x₁", y="x₂", row="variance", col="bias", aspect=1, height=3);fig.set(xlim=(-1.25,1.25), ylim=(-1.25,1.25));
Figure 4.1: Bias versus variance (imagine you are aiming at the center of the box)
Why would these two factors be in opposition? When a learning method has the capacity to capture complex behavior, it potentially has a low bias. However, that same capacity means that the learner will fit itself very well to each individual training set, which increases the potential for variance over the whole collection of training sets.
This tension is known as the bias–variance tradeoff. Perhaps we can view this tradeoff as a special case of Occam’s Razor: it’s best to choose the least complex method necessary to reach a particular level of explanatory power.
4.1.3 Learning curves
We can illustrate the tradeoff between bias and variance by running an artificial experiment with different sizes for the training datasets.
Example 4.2 We will use the handwritten digits data in an experiment with a decision tree classifier of fixed depth:
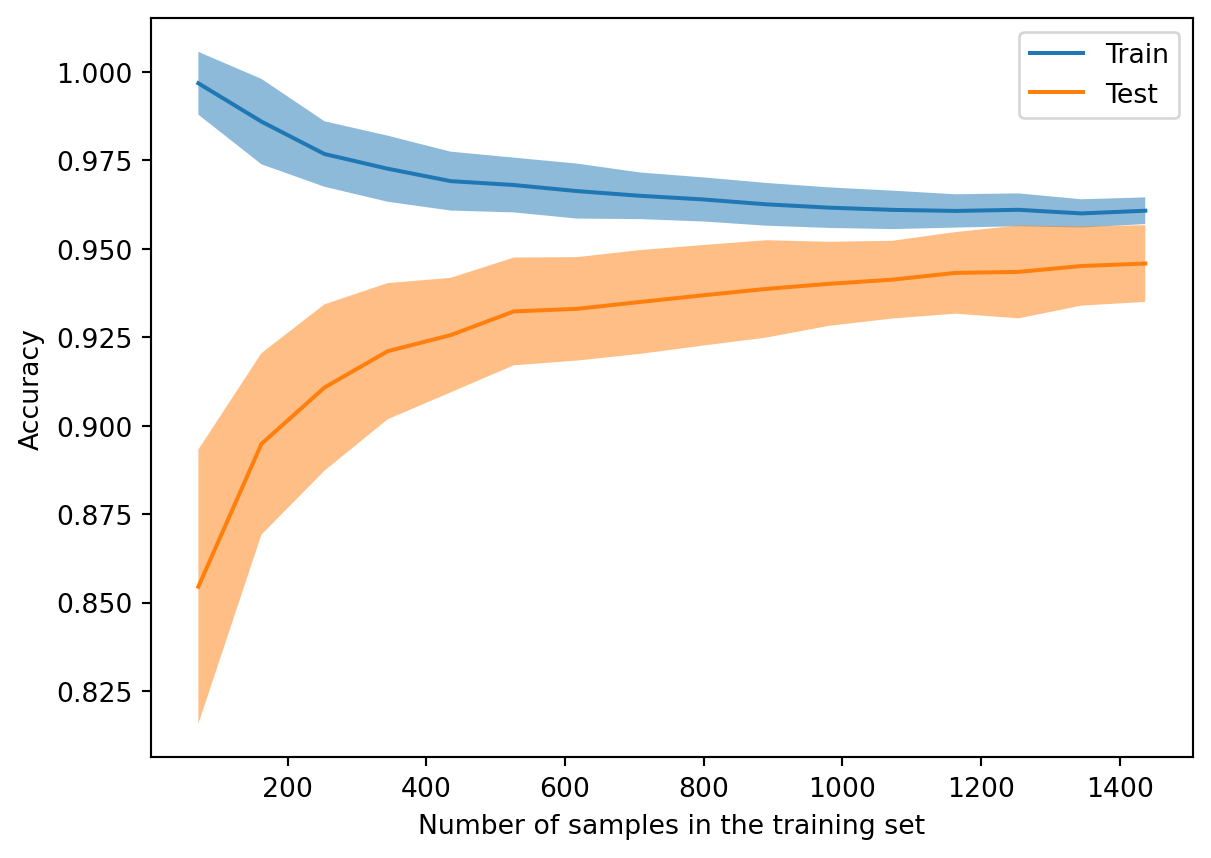
from sklearn.model_selection import LearningCurveDisplay, StratifiedShuffleSplitds = datasets.load_digits() X, y = ds["data"], ds["target"]==8tree = DecisionTreeClassifier(max_depth=4)LearningCurveDisplay.from_estimator( tree, X, y, random_state=302, cv=StratifiedShuffleSplit(n_splits=50, test_size=0.2, random_state=19716), train_sizes=np.linspace(0.05, 1, 16), score_name="Accuracy", score_type="both", # training and testing scores n_jobs=-1# use all processors )
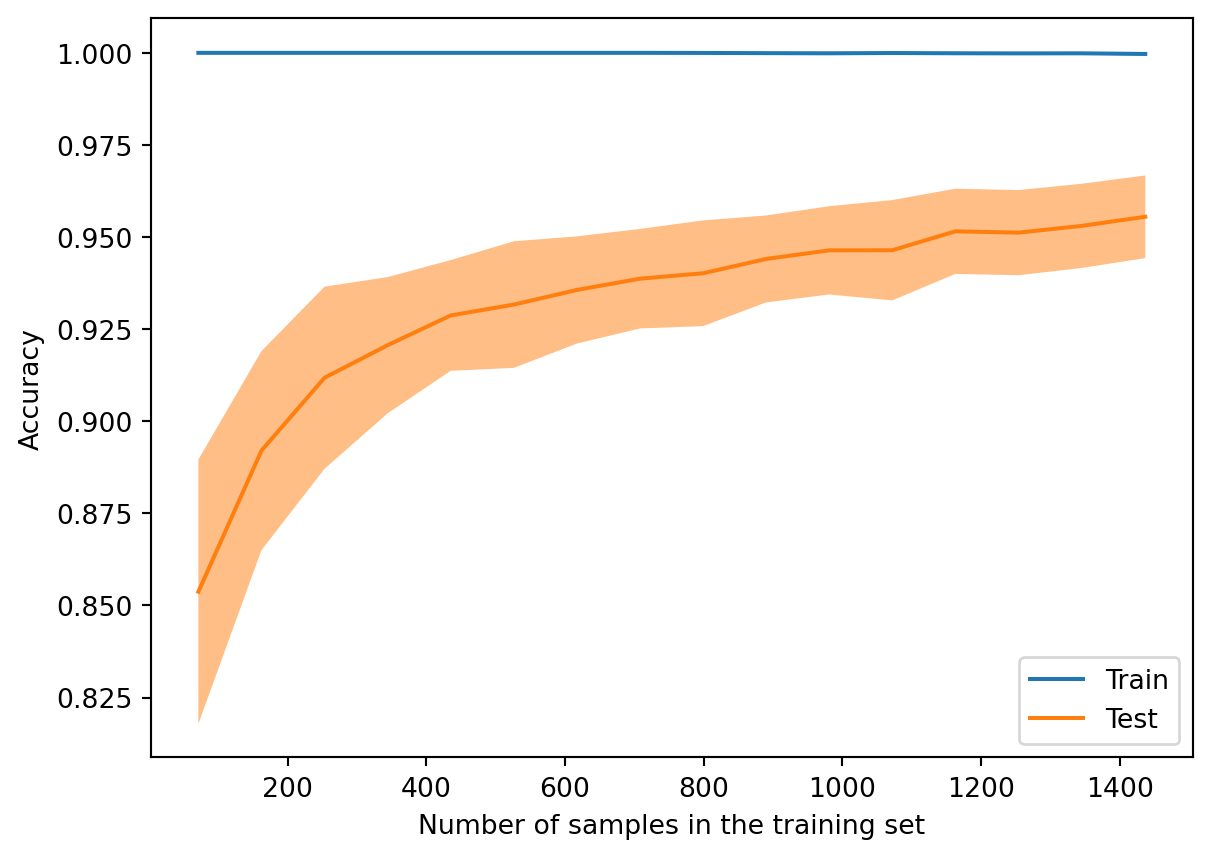
The plot above shows learning curves resulting from experiments over 100 different training sets at various sizes selected randomly from the full set. The solid lines and ribbons show the means and standard deviations, respectively, for each training set size.
The model in the experiment is a decision tree of depth 4. When the training set is tiny, the model can represent it very well. But those results generalize poorly, and the testing score is much lower and shows a lot of variance. As the training set size increases, the model cannot fit it as well (bias increases), but both the testing scores and training scores show less variance due to better generalization.
When you see a large gap between training and test errors, you should suspect that the learner may not generalize well. Ideally, you could bring more data to the table, perhaps by artificially augmenting the training examples. If not, you might as well decrease the resolving power of your learner, because the excess power is likely to make things no better, and maybe worse.
4.2 Overfitting
One important factor we have not yet considered is noise in the training data—that is, erroneous labels. If a learner responds too adeptly to isolated wrong cases, it will also respond incorrectly to other nearby inputs. This situation is known as overfitting.
4.2.1 Overfitting in kNN
To illustrate overfitting, let’s use a really simple classification problem: a single feature, with the class being the sign of the feature’s value. (We arbitrarily assign zero to have class \(+1\).)
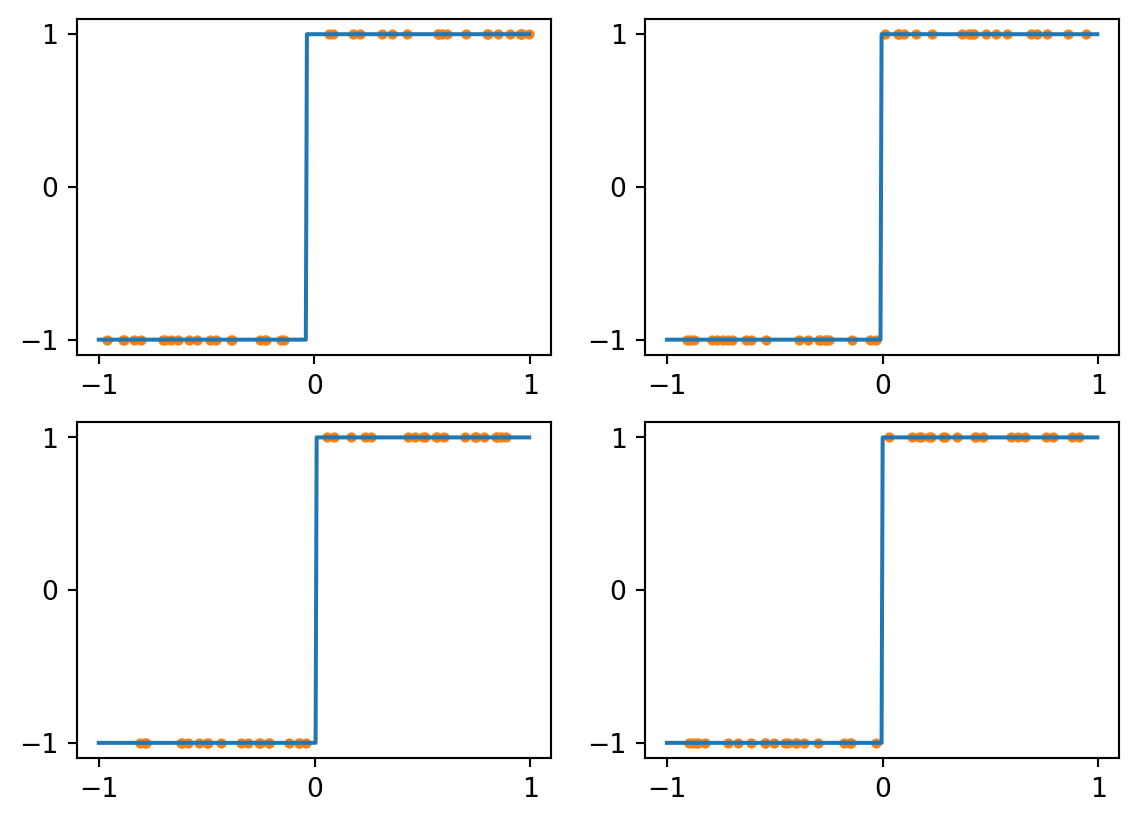
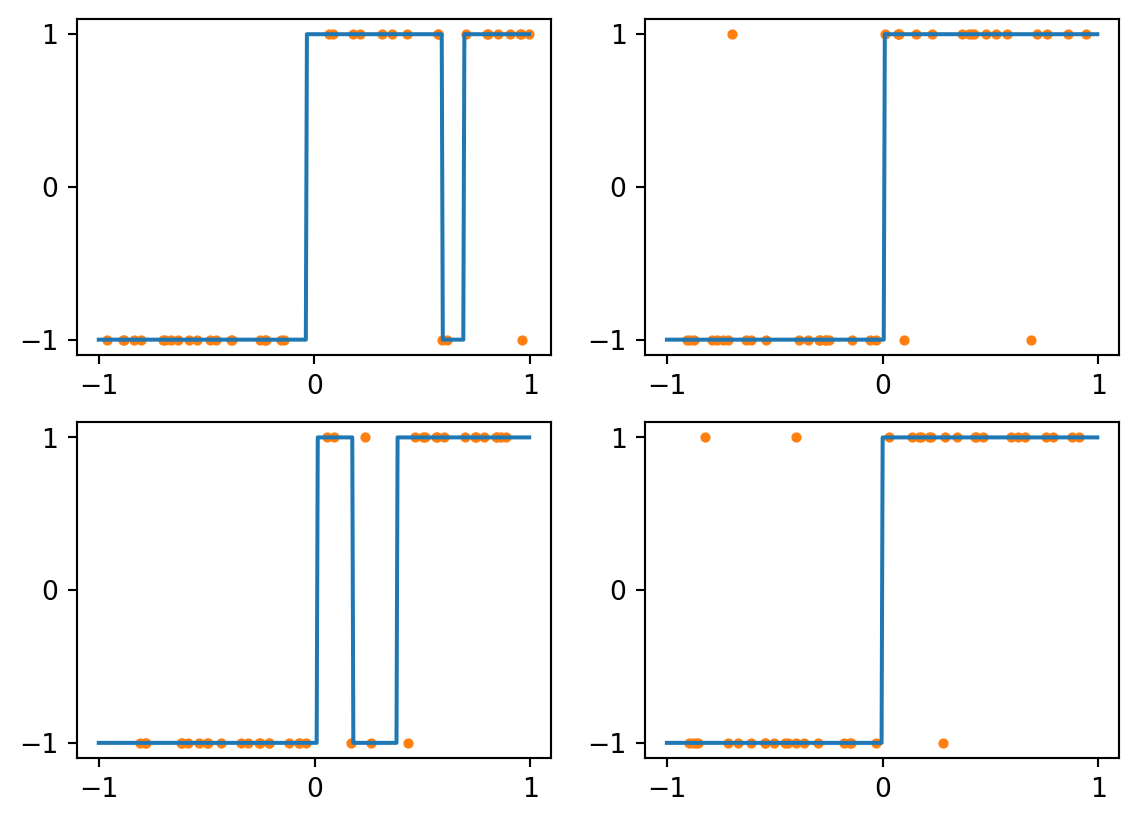
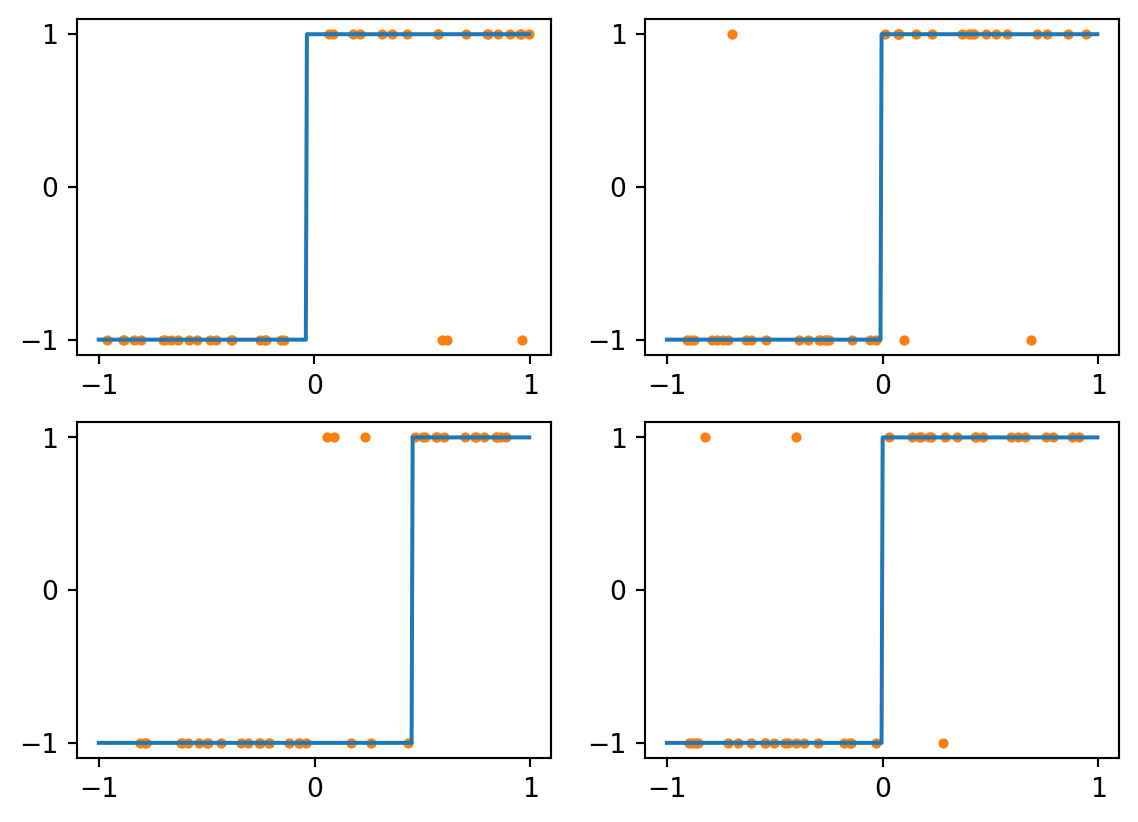
Consider first a kNN classifier with \(k=1\). The class assigned to each value is just that of the nearest training example, making for a piecewise constant labelling. Here are the results for four different training sets, each of size 40:
Figure 4.2: kNN with k=1 and perfect data
As you can see above, all four results are quite good. The only errors are for queries near zero.
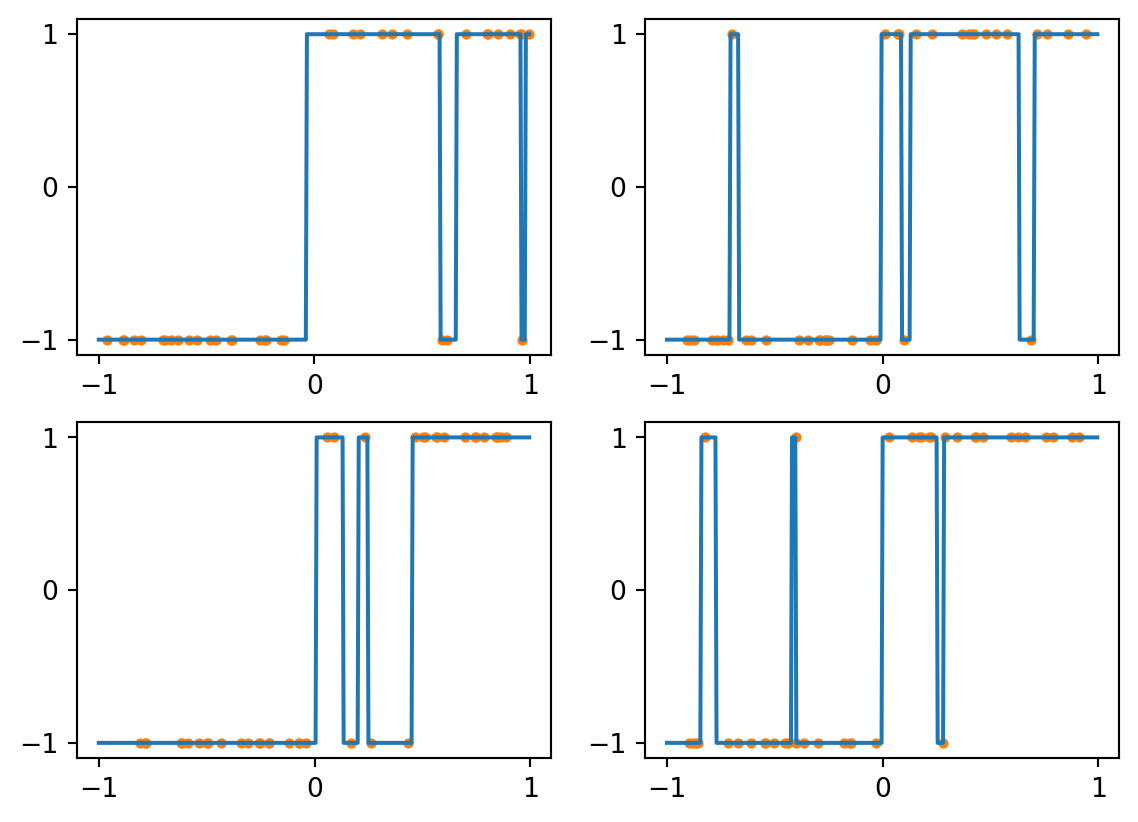
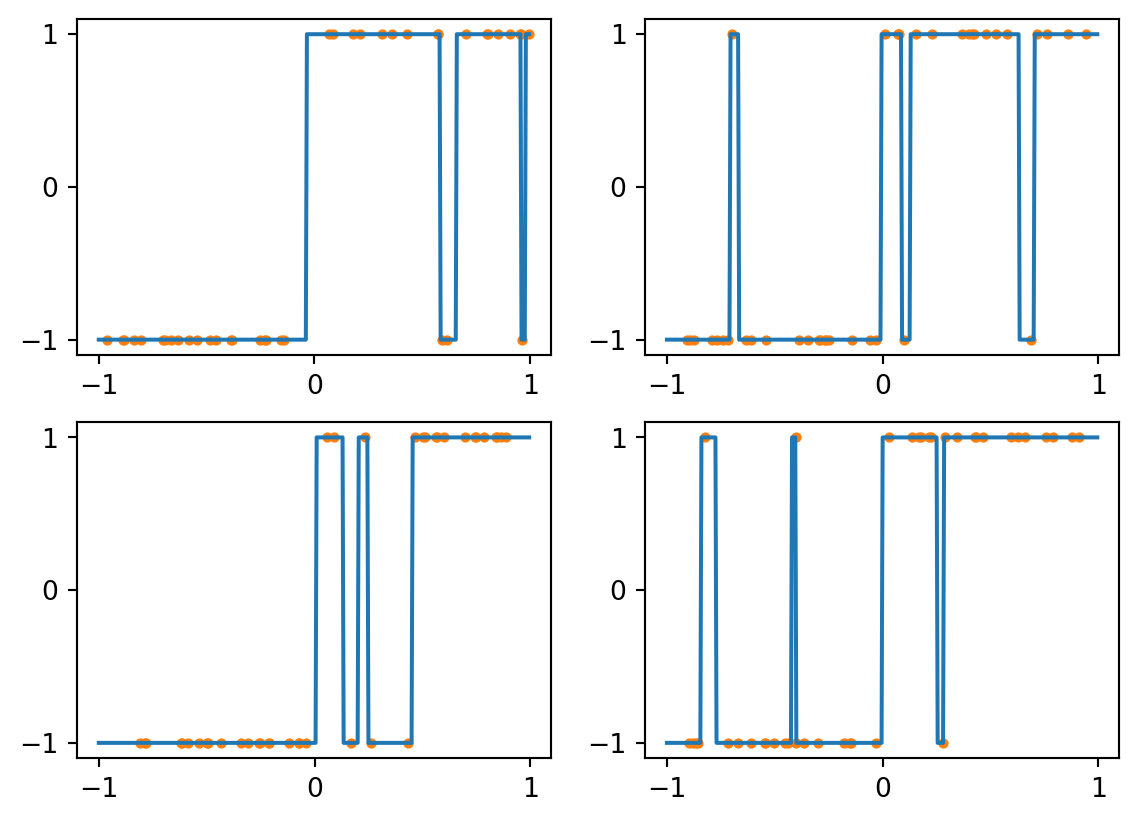
Now suppose we use training sets that have just 3 mislabeled examples each. Here are some resulting classifiers:
Figure 4.3: kNN with k=1 and noisy data
Every sample is its own nearest neighbor, so this classifier responds to noisy data by reproducing it perfectly, which interferes with the larger trend we actually want to capture. We can generally expect such overfitting with \(k=1\), for which the decision boundary can be complex.
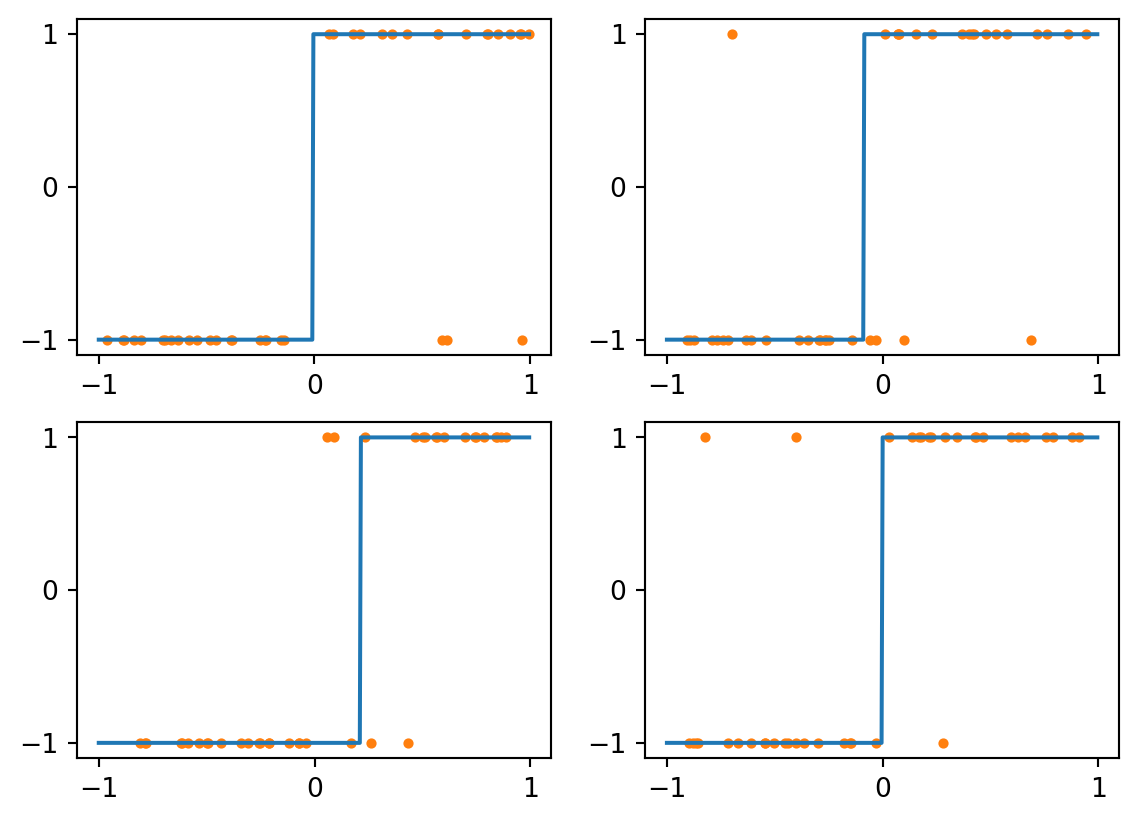
Now let’s bump up to \(k=3\). The results are more like we want, even with noisy data:
Figure 4.4: kNN with k=3 and noisy data
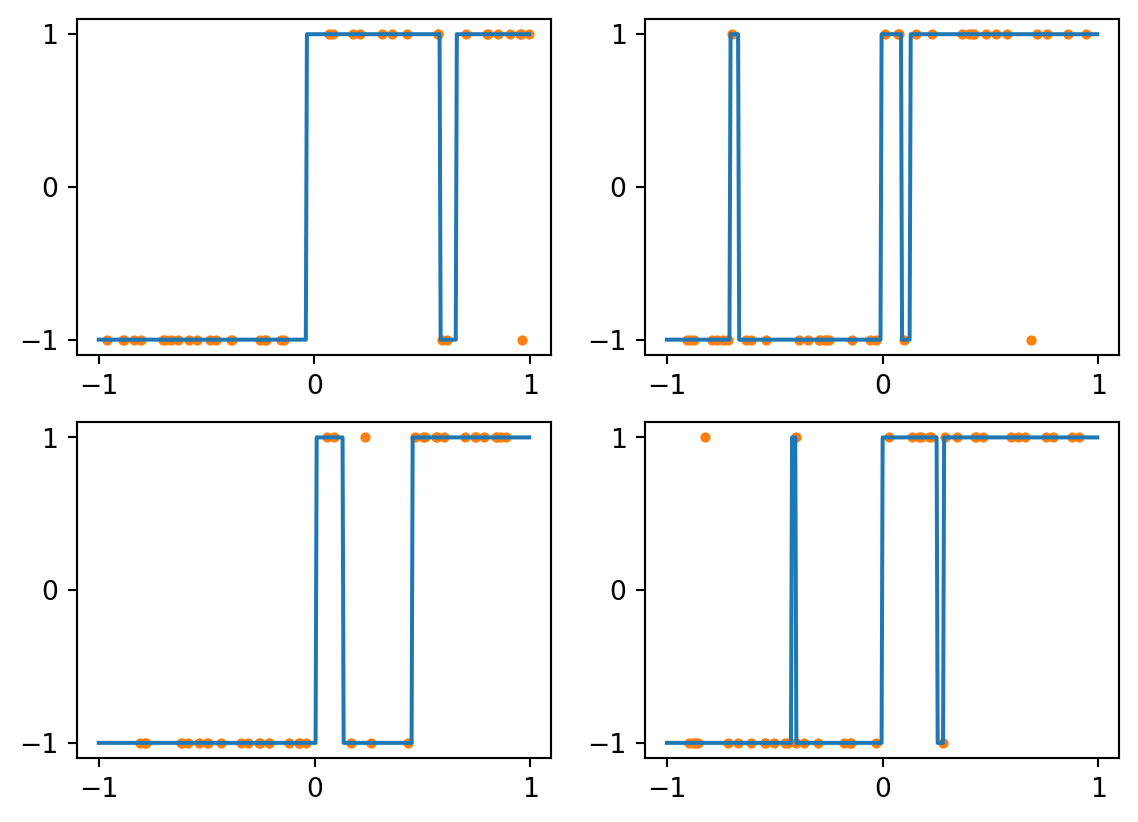
The voting mechanism of kNN allows the classifier to ignore isolated bad examples. If we continue to \(k=7\), then the 3 outliers will never be able to outvote the correct values:
Figure 4.5: kNN with k=7 and noisy data
Caution
The lesson here is not simply that “bigger \(k\) is better.” In the case of \(k=21\) above, for example, the classifier will predict the same value everywhere, which we could describe as underfitting the data.
4.2.2 Overfitting in decision trees
As mentioned in Example 4.1, the depth of a decision tree correlates with its ability to divide the samples more finely. For \(n=40\) values, a tree of depth 6 is guaranteed to reproduce every sample value perfectly. Thus, with noisy data, we see clear signs of overfitting:
Figure 4.6: Decision tree with depth=6 and noisy data
Using a shallower tree reduces the extent of overfitting:
Figure 4.7: Decision tree with depth=3 and noisy data
We can eliminate the overfitting completely and get a single point as the decision boundary, although its location still might not be ideal:
Figure 4.8: Decision tree with depth=2 and noisy data
4.2.3 Overfitting and variance
The tendency to fit closely to training data also implies that the learner may have a good deal of variance in training (see Figure 4.3, and Figure 4.6, for example). Thus, overfitting is often associated with a large gap between training and testing errors, as observed in Section 4.1.
Example 4.3Example 4.2 showed that a decision tree of depth 4 had a closing gap between scores for training and testing sets as the training set size grew. Now look at what happens for a much deeper decision tree:
The testing scores increase with the training set size, which is good, but the training score remains stuck at 100% and the gap between training and test never fully closes. In effect, the model can perfectly reproduce its training set but never knows what it doesn’t see. The final score of this more-complex tree is not appreciably better than that of the simpler tree in Example 4.2. All of the extra resolving power went to fixing details that don’t generalize.
4.3 Ensemble methods
When a relatively expressive learning model is used, overfitting and strong dependence on the training set are possible. One meta-strategy for reducing training variance without decreasing the model expressiveness is to use an ensemble method. The idea of an ensemble is that averaging over many different training sets will reduce the variance that comes from overfitting. It’s a way to simulate the computation of expected values.
Definition 4.4 In bootstrap aggregation, or bagging for short, samples are drawn randomly from the original training set. Usually, this is done with replacement, which means that some samples might be selected multiple times.
Why does bagging work? It comes down to the way that bias and variance behave. Suppose we produce \(M\) probabilistic binary classifiers, \(\hat{f}_1,\ldots,\hat{f}_M\), that are identical except in having received independent training sets. They create the (probabilistic) bagging classifier \[
\hat{F}(x) = \frac{1}{M} \sum_{m=1}^M \hat{f}_m(x).
\]
The bias of the bagging classifier is the expectation of \[
y - \hat{F}(x) = \frac{1}{M} (My) - \frac{1}{M} \sum_{m=1}^M \hat{f}_m(x) = \frac{1}{M} \sum_{m=1}^M \left( y - \hat{f}_m(x) \right).
\]
This is simply the mean of the constituent classifier biases. Since the original classifiers are identical, in expected value they all have the same bias, and we conclude that the bias of the bagging classifier has is the same as its constituents. But it can be derived that the variance of the bagging predictor is \(1/M\) times that of the constituent classifiers. We should therefore expect bagging to work best with highly expressive classifiers that have low bias and large variance. These tend to occur in large-depth decision trees and small-\(k\) kNN classifiers, for example.
Note
Bagging explains the wisdom of crowds. For instance, if many people are asked to independently guess the number of jellybeans in a large jar, the mean of the guesses will tend to be much closer to the true value than most individuals’ guesses are.
Scikit-learn has a BaggingClassifier that automates the process of generating an ensemble from just one basic type of estimator.
Example 4.4 Here is a dataset collected from images of dried beans:
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
We can use the trained ensemble object much like any learner. For example, here is the prediction obtained for the last row of the training set:
query = X_test.iloc[-1:,:]p_hat = ensemble.predict_proba(query)print(f"Predicted ensemble probability of True on query is {p_hat[0][1]:.2%}")
Predicted ensemble probability of True on query is 52.67%
Internally, the estimators_ field of the ensemble object is a list of the individual trained classifiers. With a little work, we could find out the prediction for True from every constituent:
pm = [ model.predict_proba(query.to_numpy())[0,1] for model in ensemble.estimators_ ]pm[:6] # first 6 predictions
The ensemble takes the average of this list to create its prediction:
print(f"Mean probability of True for query is {np.mean(pm):.2%}")
Mean probability of True for query is 52.67%
The result above matches what we got by predicting directly from the ensemble, which is the normal mode of operation.
Over the testing set, we find that the ensemble has improved the AUC score:
p_hat = ensemble.predict_proba(X_test)auc = roc_auc_score(y_test==True, p_hat[:,1]) # columns are for [False, True]print(f"AUC for ensemble is {auc:.4f}")
AUC for ensemble is 0.9839
There is a significant catch in that the theory requires the constituent learners to be uncorrelated, which is less true as the size of the bagging sample grows relative to the original training set. This can somewhat counterintuitively lead to better results by training on smaller individual training sets.
Note
An ensemble of decision trees is known as a random forest. We can use a RandomForestClassifier to accomplish the same thing as a bagged decision tree ensemble.
Example 4.5 If we repeat the above but reduce the bagging training sets to just 20% of the full training set, we get a slightly better result:
ensemble = BaggingClassifier( pipe, max_samples=0.2, n_estimators=100, random_state=18621 )ensemble.fit(X_train, y_train)p_hat = ensemble.predict_proba(X_test)auc = roc_auc_score(y_test==True, p_hat[:,1]) # columns are for [False, True]print(f"AUC for the new ensemble is {auc:.4f}")
AUC for the new ensemble is 0.9873
We may get better results by increasing the size of the ensemble, too, though in this case there isn’t much room left for improvement.
Example 4.6 Let’s work again with the forest cover dataset. It’s got over 500,000 samples and 54 features:
We’ll turn this into a binary classification by looking for just one of the possible label values:
X = forest["data"]y = forest["target"] ==1X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, shuffle=True, random_state=302)
How should we best make use of all that data? We can use a fairly deep decision tree without fear of overfitting, and the result is not bad:
tree = DecisionTreeClassifier(max_depth=12) tree.fit(X_train, y_train)from sklearn.metrics import f1_scoreF1 = f1_score(y_test, tree.predict(X_test) )print(f"F₁ for a single tree is {F1:.4f}")
F₁ for a single tree is 0.8106
A simple averaging over the same type of tree actually does worse here:
from sklearn.ensemble import RandomForestClassifierrf = RandomForestClassifier( max_depth=12, max_samples=0.2, n_estimators=100, n_jobs=-1 )rf.fit(X_train,y_train)F1 = f1_score(y_test, rf.predict(X_test) )print(f"F₁ for a random forest is {F1:.4f}")
F₁ for a random forest is 0.7743
It’s possible that these trees are too correlated. We can combat that by exaggerating their degree of overfitting:
rf = RandomForestClassifier( max_depth=24, max_samples=0.2, n_estimators=100, n_jobs=-1 )rf.fit(X_train,y_train)F1 = f1_score(y_test, rf.predict(X_test) )print(f"F₁ for a taller forest is {F1:.4f}")
F₁ for a taller forest is 0.9027
In fact, we can decorrelate even better by only using random subsets of the features on each tree. Here, for example, we construct the ensemble so that each tree randomly selects 50% of the original 54 dimensions to work with:
rf = RandomForestClassifier( max_depth=24, max_features=0.5, max_samples=0.2, n_estimators=100, n_jobs=-1 )rf.fit(X_train,y_train)F1 = f1_score(y_test, rf.predict(X_test) )print(f"F₁ for a taller, skinnier forest is {F1:.4f}")
F₁ for a taller, skinnier forest is 0.9403
Ensembles can be constructed for any individual model type. Their chief disadvantage is the need to repeat the fitting process multiple times, although this can be mitigated by computing the fits in parallel.
4.4 Validation
We now return to the opening questions of this chapter: how should we determine optimal hyperparameters and algorithms?
It’s tempting to compute some test scores over a range of hyperparameter choices and simply choose the case that scores best. However, if we base hyperparameter optimization on a fixed testing set, then we are effectively learning from that set! The hyperparameters might become too tuned—i.e., overfit—to our particular choice of the test set.
To avoid this pitfall, we can split the data into three subsets for training, validation, and testing. The validation set is used to tune hyperparameters. Once training is performed at values determined to be best on validation, the test set is used to assess the generalization of the optimized learner.
Unfortunately, a fixed three-way split of the data further reduces the amount of data available for training, so we often turn to an alternative.
4.4.1 Cross-validation
In cross-validation, each learner is trained multiple times using unique training and validation sets drawn from the same pool.
Definition 4.5 The steps for \(k\)-fold cross-validation are as follows:
Divide the original data into training and testing sets.
Further divide the training data set into \(k\) roughly equal parts called folds.
Train a learner using folds \(2,3,\ldots,k\) and validate on the cases in fold 1. Then train another learner on folds \(1,3,\ldots,k\) and validate against the cases in fold 2. Continue until each fold has served once for validation.
Select the hyperparameters producing the best validation score and retrain on the entire training set.
Assess performance using the test set.
Example 4.7 Here is how 16 elements can be split into 4 folds:
from sklearn.model_selection import KFoldkf = KFold(n_splits=4, shuffle=True, random_state=0)for train,test in kf.split(range(16)): print("train:", train, ", test:", test)
A different variation is stratified\(k\)-fold, in which the division in step 2 is constrained so that the relative membership of each class is the same in every fold as it is in the full training set. This is advisable when one or more classes is scarce and might otherwise become underrepresented in some folds.
Example 4.8 Let’s apply cross-validation to the beans dataset.
The low variance across the folds that we see above is reassurance that they are representative. Conversely, if the scores were spread more widely, we would be concerned that there was strong dependence on the training set, which might indicate overfitting.
Important
Note in Example 4.8 that the dataset was not split into fixed training and test sets. Instead, the cross-validation process itself was used to estimate the generalization error.
4.4.2 Hyperparameter tuning
If we perform cross-validations as we vary a hyperparameter, we get a validation curve.
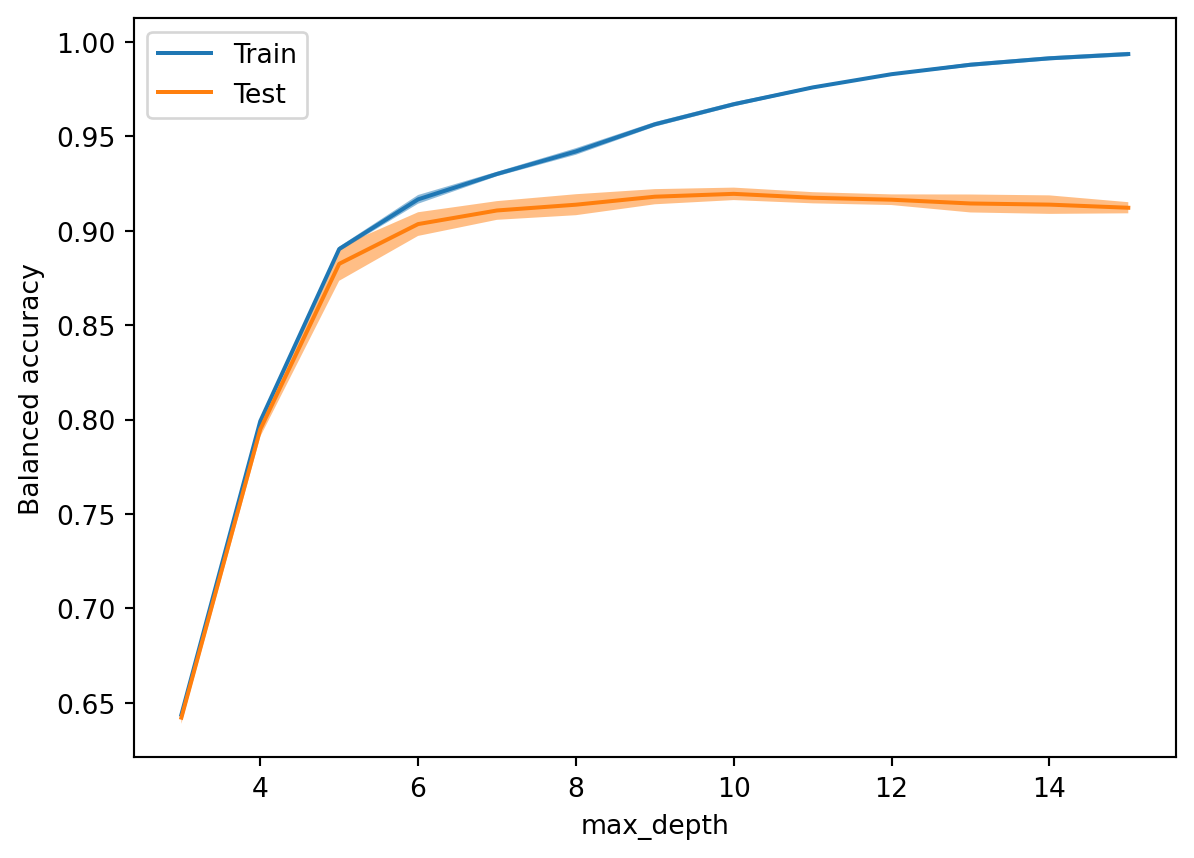
Example 4.9 Here is a validation curve for the maximum depth of a decision tree classifier on the beans data:
from sklearn.model_selection import ValidationCurveDisplayfrom sklearn.model_selection import StratifiedKFoldValidationCurveDisplay.from_estimator( DecisionTreeClassifier(random_state=302), X, y, param_name="max_depth", param_range=range(3, 16), cv=StratifiedKFold(n_splits=6, shuffle=True, random_state=19716), scoring="balanced_accuracy", n_jobs=-1 )
The score increases nicely until the depth is 6, after which it levels off, with an increasing gap between training and testing error, suggesting that overfitting settles in. We conclude that 6 or 7 is a good choice for the maximum depth.
4.4.2.1 Grid search
When there is a single hyperparameter in play, the validation curve is useful way to optimize it. When multiple hyperparameters are available, it’s common to perform a grid search, in which we try cross-validated fitting using every specified combination of parameter values.
Example 4.10 Let’s work with a dataset on breast cancer detection:
Best parameters:
{'knn__metric': 'manhattan', 'knn__n_neighbors': 4, 'knn__weights': 'distance'}
Best score:
0.9734627184207016
Each fitted grid search object is itself a classifier that was trained on the full training set at the optimal hyperparameters:
dt_score = f1_score( y_test, grid_dt.predict(X_test) )knn_score = f1_score( y_test, grid_knn.predict(X_test) )print(f"best tree f1 score: {dt_score:.5f}")print(f"best knn f1 score: {knn_score:.5f}")
best tree f1 score: 0.94915
best knn f1 score: 0.99187
Note
It may be instructive to rerun the competition above using different random seeds. The meaningfulness of the results is limited by their sensitivity to such choices. Don’t let floating-point values give you a false feeling of precision!
4.4.2.2 Alternatives to grid search
Grid search is a brute-force approach. It is embarrassingly parallel, meaning that different processors can work on different locations on the grid at the same time. But it is usually too slow for large training sets, or when the search space has more than two or three dimensions. In such cases you can try searching over crude versions of the grid, perhaps with just part of the training data, and gradually narrow the search while using all the data. When desperate, one may try a randomized search and to guide the process with experience and intuition.
Exercises
Exercise 4.1 (4.1) One (dumb) algorithm for binary classification is to always predict the positive outcome.
(a) Considered over all possible training sets, does this method have a high training variance or low training variance? Explain.
(b) Considered over all possible testing sets, does this method have a high testing bias or low testing bias? Explain.
Exercise 4.2 (4.3) Suppose you are trying to fit this ground-truth one-dimensional classifier defined on positive integers:
\[
y = f(m) =
\begin{cases}
0, & \text{ if $m$ is odd}, \\
1, & \text{ if $m$ is even}.
\end{cases}
\]
Here are three individual classifiers:
\[
\begin{aligned}
\hat{f}_a(m) &= 1 \text{ for all $m$}, \\
\hat{f}_b(m) &=
\begin{cases}
0, & \text{ if $m = 1,2,5,6,9,10,\dots$}, \\
1, & \text{ if $m = 3,4,7,8,11,12,\dots$ },
\end{cases} \\
\hat{f}_c(m) &=
\begin{cases}
0, & \text{ if $m = 1,4,5,8,9,12,\dots$}, \\
1, & \text{ if $m = 2,3,6,7,10,11,\dots$}.
\end{cases}
\end{aligned}
\]
Let the testing set be \(1,2,3,\ldots,12\).
(a) Compute the accuracy of each classifier on the testing set.
(b) Compute the accuracy of the majority-vote ensemble of the three classifiers on the testing set. That is, the classifier with \(\hat{f}(m) = 1\) if at least two of the member classifiers are 1, and \(\hat{f}(m) = 0\) otherwise.